机器学习实战(一)
前言
作者大四在读,恰逢毕设时间,毕设选题将会以GAN技术(生成式对抗网络技术)为核心展开工作。然而作者在这之前,并没有任何与智能图片生成——也就是“有关于深度学习的图像生成技术”打过交道。作者首先接触到了B站台湾大学李宏毅教授的GAN课程,奈何缺乏基本的机器学习、神经网络、深度学习等前要知识,听到第二节课就已经云里雾里了(很烦~),最后我决定从头开始,毕竟磨刀不误砍柴工,打好基础才能实现上层目标。根据人工智能领域的分支关系图,我决定先从机器学习开始。
学习路线(机器学习)
网课(理论)
理论部分我采用网课形式。在阿里巴巴旗下的子平台阿里云全球培训中心:开发者课堂中有着众多领域的学习路线,其中包含人工智能学习路线,阶段一即是机器学习入门。
网课老师语速和节奏较慢,关键是在一些概念性的问题上讲解通俗易懂。不过到中期算法讲解之后,由于学习机器学习数学知识非常必要,内容不可能轻易让人理解。(学习机器学习前,数学中的线性代数和概率统计是非常重要的内容)
书籍(实战)
其实在书籍方面,最有口皆碑的就是周志华教授的《机器学习》一书,也被称作“西瓜书”,其内容非常经典而且适合学习。

不过在作者学校的图书馆此书已经被借空,而且此书的学习实际上要求学生已经掌握了一些人工智能的基础知识,因此最后,我选择了黄佳编著的《零基础学人工智能》一书,里面包含若干个机器学习项目实例,并附有学习资源和代码。这些资源在书籍扉页可以找到(https://www.epubit.com/bookDetails?id=UB7245bf2ca7715)。
语言及框架
python。这个其实也不用多说了,众所周知搞人工智能最好的编程语言。不过关于人工智能框架需要说一点,在学习过程中,机器学习主要接触的是scikit-learn库,深度学习主流的框架有三个:keras、tensorflow、pytorch。书籍中所使用的皆为keras,而我本人的项目也会涉及到tensorflow。
平台及环境
我使用的平台有两个,分为本地环境和线上环境。本地环境使用anaconda创建一个python环境,并安装jupyter notebook库便于写代码。但是由于各种各样的原因,在研究过程中我还需要用到一个线上平台,及google colab(需要科学上网),colab 支持用户在google的服务器上使用jupyter notebook,而且最关键的两点是:1.你不需要特地配置keras、tensorflow等环境(本地配置的时候可能会存在各种问题,例如库版本、库间对应版本……),它已经帮你配好了,只需要开写代码就行!2.一般做机器学习项目需要电脑硬件比较好,但是colab支持用户设备不需要GPU硬件——就是你电脑没显卡也没事儿,用的是服务器的GPU,运行代码速度照样嘎嘎快(没有那么夸张)
书中推荐的平台还有一个叫做kaggle,该平台兴办机器学习竞赛,而且同样向平台用户提供GPU,但是每周使用有一定限制。
实例一:加州房价预测
该实例来源自参考书籍中,作为读者第一个接触到的实例,不需要看懂每行代码,只需要观察机器学习项目的代码结构以及思路即可。
1 | import pandas as pd # 导入Pandas,用于数据读取和处理 |
- 使用DataFrame数据结构的head方法显示数据集中的部分信息
- 在jupyter notebook中按ctrl+enter运行一个块儿(cell)中的代码
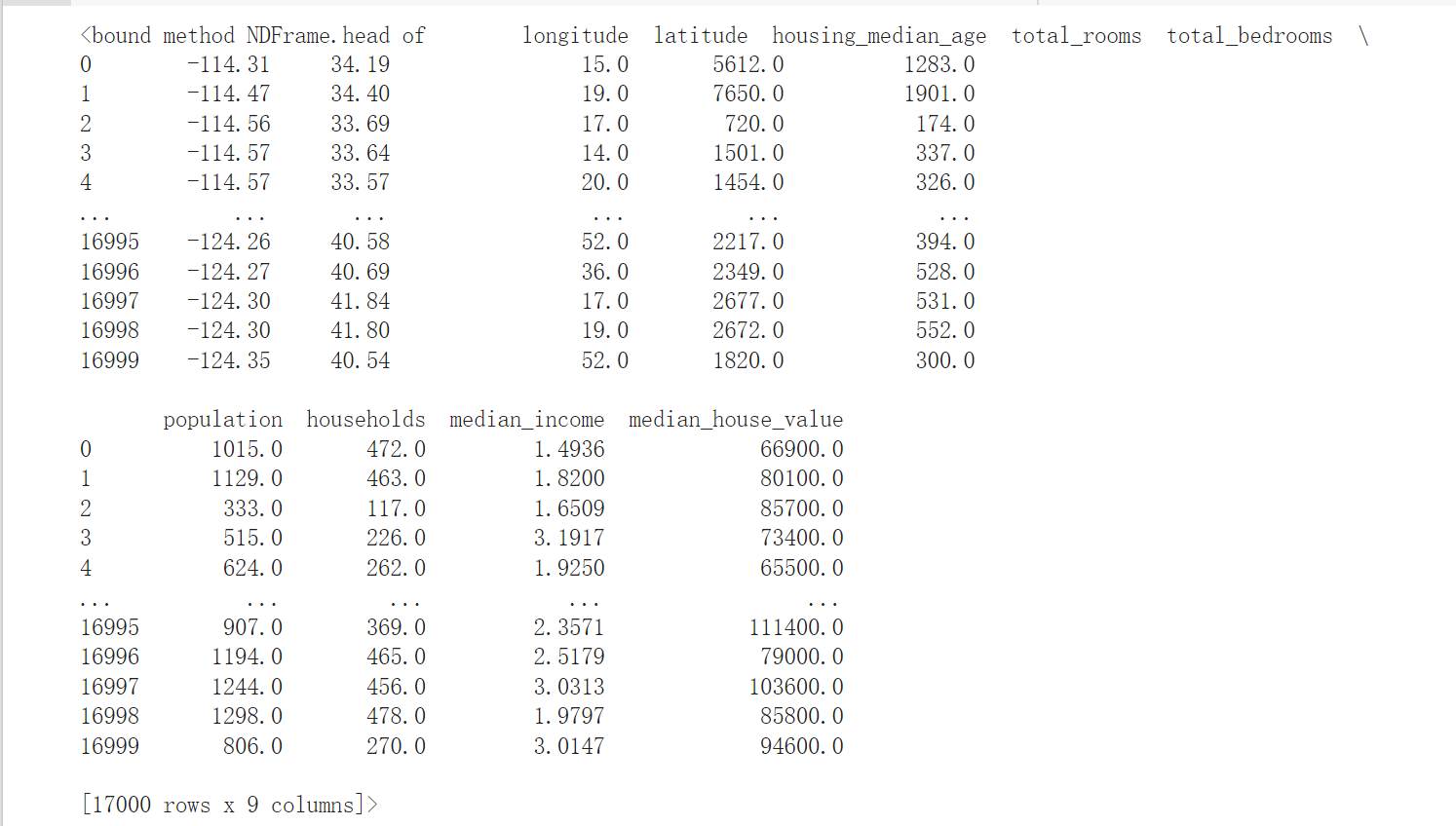
该数据集记录了加州各地区的房价统计信息。看到最后一列就是房价的统计结果,很直观可以看出,影响这个结果的就是前几列的因素:经度、纬度、房屋平均年龄、房屋数量、家庭收入中位数。
因此我们可以说,前面这些影响因素就是数据集的特征,最后这列我们要的结果就是标签。我们的目标呼之欲出,我们要从这个数据集中归纳(拟合)出一个函数f(经度,纬度,……,家庭收入中位数)->房价。有了这个函数之后,我们去加州随便找一个地方的房子,都能算出这个房子的价格了,然后你就能算算你买不买得起了(笑)。
现在我们就来做找函数这件事。
1 | X = df_housing.drop("median_house_value", axis=1) # 构建特征集 |
- 在机器学习领域特征集一般用大写X表示,标签集一般用小写y表示,可能是习惯?
- 使用drop方法(该方法来自于pandas库中的dataframe数据结构)把最后一列字段去掉形成特征集
1 | from sklearn.model_selection import train_test_split # 导入sklearn工具库 |
- 把数据集拆分成两块,80%的数据用于产生我们需要的函数f,另外20%的数据用于带入数据比较结果,看看这个函数找的对不对。在网课内容中,我们知道,不用整个数据集找函数是怕找到的函数过拟合——即看起来f效果不错(对该数据集来说),但假设你用额外的新数据带入,f的效果可能会不好,但这在你带入新数据前都无法知道。
接下来开始训练机器,首先我们需要找一个适合该问题的模型。这里选择LinearRegression(线性回归)方法。
1 | from sklearn.linear_model import LinearRegression |
- fit方法即可以训练机器,拟合函数,函数的具体形式已经在model中了,我们没有直接看到。下面进行预测(这里参与预测的数据就是刚刚分离出来的20%的数据咯!)
1 | y_pred=model.predict(X_test) # 预测验证集的y值 |

- predict方法应该是用上了刚才模型训练得到的函数f,可得到y_pred。
- score方法是一个机器学习模型的评估指标,给出了预测值的方差与总体方差之间的差异。根据score中的参数,个人觉得score里面应该是先用了predict方法求取了y_pred,然后进行比较。公式如图:

接下来我们使用matplotlib库把函数可视化。
1 | import matplotlib.pyplot as plt |
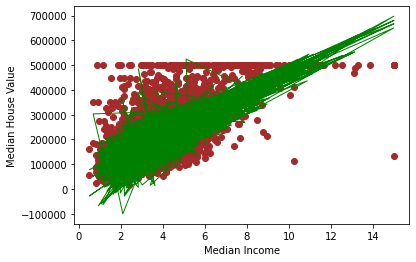
- 注意图里看上去有很多线,但实际上它是一条线,因为plot只是把点与点连起来画出一条线,也就是说代码展示了median_income和y_pred的大概函数关系,大概是线性增长的。
基本机器学习术语
| 术语 | 定义 | 数学描述 | 示例 |
|---|---|---|---|
| 数据集 | 数据的集合 | {(X~1~,y~1~), …, (X~n~,y~n~)} | 1000个北京市房屋的面积、楼层、位置、朝向,以及部分房价信息的数据集 |
| 样本 | 数据集中的一条具体记录 | (X~1~,y~1~) | 一个房屋的数据记录 |
| 特征 | 用于描述数据的输入变量 | {X~1~,X~2~, …, X~N~}也是一个向量 | 面积(X~1~)、楼层(X~2~)、位置(X~3~)、朝向(X~4~) |
| 标签 | 要预测的真实事物或结果,也称为目标 | y | 房价 |
| 有标签样本 | 有特征、标签、用于训练模型 | (X,y) | 800个北京市房屋的面积、楼层、位置、朝向、以及房价信息 |
| 无标签样本 | 有特征,无标签 | (X,?) | 200个北京市房屋的面积、楼层、位置、朝向,但是无房价信息 |
| 模型 | 将样本的特征映射到预测标签 | f(x),其实就是函数 | 通过面积、楼层、位置、朝向这些信息来确定房价的函数 |
| 模型中的参数 | 模型中的参数确定了机器学习的具体模型 | f(x)函数的参数 | 如f(x)=5x+6中的5和6 |
| 模型的映射结果 | 通过模型映射出无标签样本的标签 | y’ | 200个被预测出来的房价 |
| 机器学习 | 通过学习样本数据,发现规律,得到模型的参数,从而得到能预测目标的模型 | 确定f(x)和其参数的过程 | 确定房价预测函数和具体参数的过程 |
特征向量中有几个特征,就说明这个特征是几维特征
y^'^有时候也被成为y-hat,写作y上面带一个^
机器学习项目实战架构与MNIST数据集
机器学习项目的实际过程主要分为以下5个环节:
- (1)问题定义。
- (2)数据的收集和预处理
- (3)模型(算法)的选择
- (4)选择机器学习模型
- (5)超参数调试和性能优化
环节一:问题定义
问题定义简单来说,就是你想要解决什么问题,它是否可以用机器学习的方法解决。
MNIST数据集相当于机器学习领域的hello world,相当经典,其中包含60000张训练图像和10000张测试图像,尺寸都为28px*28px,如下图所示。
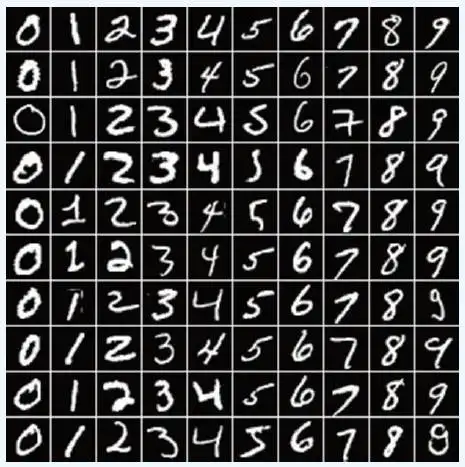
此处要解决的问题是:将手写数字灰度图像分类为0,1,2,3,4,5,6,7,8,9
环节二:数据收集和预处理
该环节主要包括以下内容:
- 原始数据的准备
- 数据的预处理
- 特征工程和特征提取
原始数据的准备
可以是自有数据(如公司的客户信息)、使用爬虫爬取的数据、开源网站下载的数据、来自youtube和维基百科的数据……
数据的预处理
- 可视化(visualization):使用excel和各种数据分析工具(如matplotlib)从各种角度看数据。
- 数据向量化(data vectorization):把原始数据格式化,使其变得机器可以读取,例如把图片转换成数字矩阵,把文字转换成one-hot编码(one-hot编码概念)。
- 处理坏数据和缺失值:常常一组数据不是所有都能用。
- 特征缩放(feature scaling):常用方法有标准化(standardization)和规范化(normalization)
特征工程和特征提取
广义上仍属于数据预处理。特征提取主要需要思考以下问题:
(1)如何选择最有用的特征给机器进行学习?
(2)如何把现有的特征进行转化、强化、组合,创建出来新的、更好的特征?
比如,对于图像数据,可以通过计算直方图来统计图像中像素强度的分布,得到描述图像颜色的特征。
实例:载入MNIST数据集
1 | import numpy as np |
X_train_image:训练集特征——图片
y_train_label:训练集标签——数字
X_test_image:测试集特征——图片
y_test_label:测试集标签——数字
- shape方法显示X_train_image张量的形状:60000表示60000张,28、28表示尺寸
数据集在输入机器学习模型之前还要做一些数据格式转换工作:
1 | from tensorflow.keras.utils import to_categorical # 导入keras.utils工具库的类别转换工作 |
- to_categorical()方法介绍
- 要增加一个维度的原因:keras要求图像数据集导入卷积神经网络时为4阶张量,最后一阶代表颜色深度,灰度图像只有一个颜色通道,所以设置值为1(如果时rgb图像那就是3咯)
- 标签[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]代表1,[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]代表2,以此类推。
环节三:选择机器学习模型
常见的模型框架有以下几种:
- 线性模型(线性回归、逻辑回归)
- 非线性模型(支持向量机、KNN)
- 基于树和集成的模型(决策树、随机森林、梯度提升树)
- 神经网络(ANN、CNN、长短期记忆网络)
在这里我们选择CNN(卷积神经网络)处理MNIST。
1 | from keras import models # 导入Keras模型,以及各种神经网络的层 |
- 这一段我也看不懂,希望以后学了就会懂吧5555
环节四:训练机器,确定参数
在这里我们需要确定模型内部参数,简单来说就是f(x)的形式呗。例如f(x)=2x+1,这里的2叫做权重,1叫做偏置。以后还会学到超参数一概念。
1 | model.fit(X_train, y_train, # 指定训练特征集和训练标签集 |
- 以上5轮训练中,准确率会逐渐提高。
- 这里的5轮就是一种超参数,是可以人为定义的且与f无关,但最后仍有可能影响训练结果。
环节五:超参数调试和性能优化
机器学习重在评估,通过评估才能知道当前模型的效率。
两个重要评估点:
- 损失函数
- 验证
本例中的损失函数已经包含在了fit方法中了。验证则可以使用以下代码:
1 | score = model.evaluate(X_test, y_test) # 在验证集上进行模型评估 |
当然,人们看到一个准确率常常没有直观的体验,虽然说这个时候机器学习项目已经结束了。那么我们单独拿一个预测结果看看对不对。
1 | pred = model.predict(X_test[3].reshape(1, 28, 28, 1)) # 预测测试集第4个数据 |
- argmax方法就是输出数组里面最大元素的索引。例如[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]就是输出2(第三个咯)。
输出结果如下:
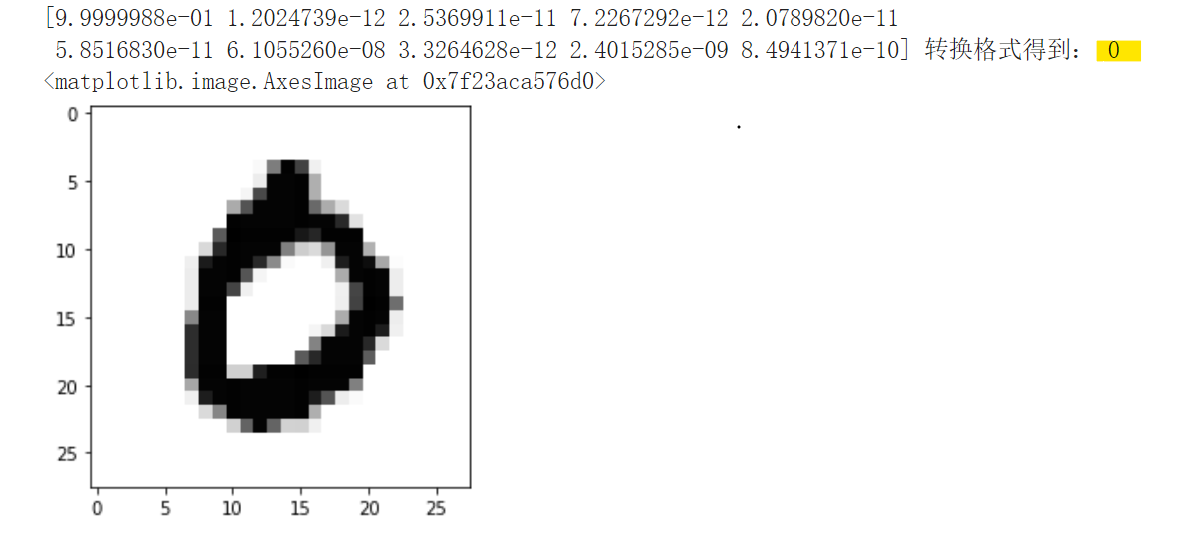
发现结果正确,都是0。
课后练习和答案(非标答)
一 列举出机器学习的类型,并说明分类的标准
答:监督学习、无监督学习、半监督学习,分类标准是已有的数据集是否有标签。
二 解释机器学习术语:什么是特征,什么是标签,什么是机器学习模型
答:特征:用于描述模型的输入数据。标签:数据的输出结果。机器学习模型:将样本特征映射到标签的一种方法。
自己导入keras的波士顿房价数据集(boston_housing),并判断哪些是标签字段。
参考两个机器学习代码,使用LinearRegression线性回归算法对波士顿房价数据集进行建模。
两者一起答:
1 | from keras.datasets import boston_housing |