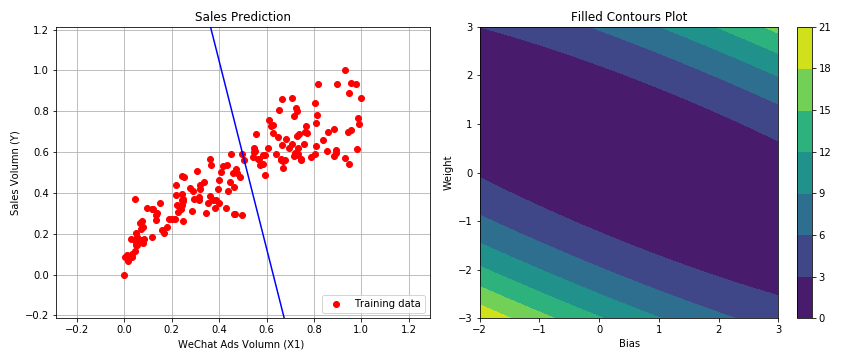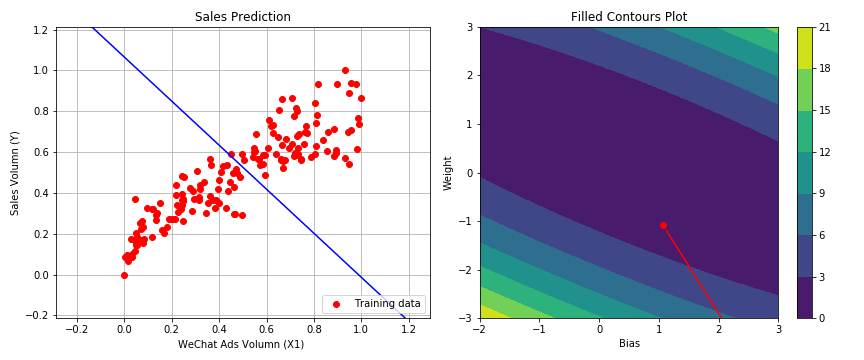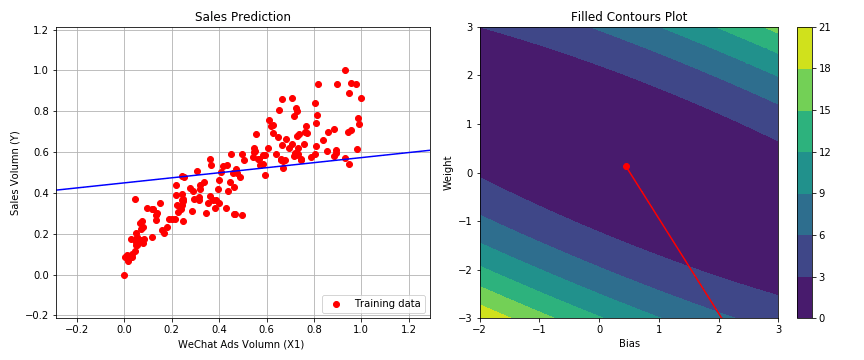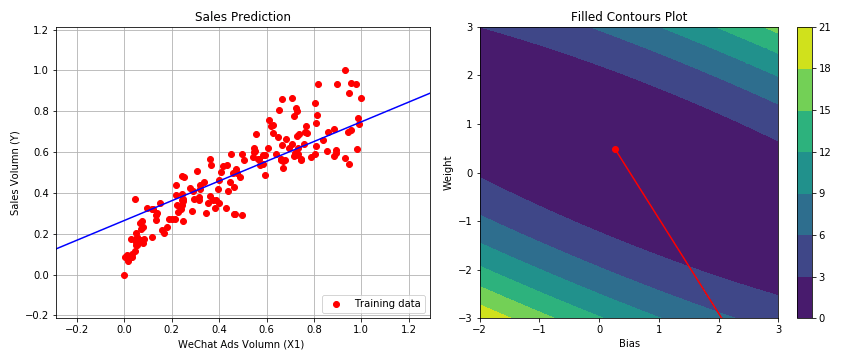
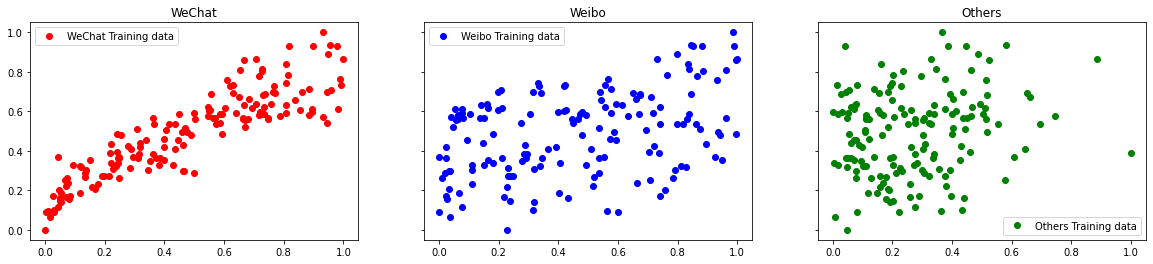
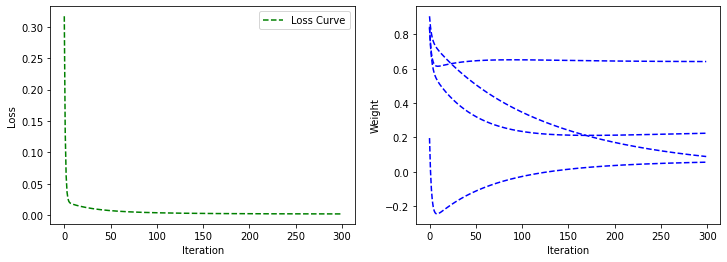
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
import matplotlib.animation as animation
theta0_vals = np.linspace(-2, 3, 100)
theta1_vals = np.linspace(-3, 3, 100)
J_vals = np.zeros((theta0_vals.size, theta1_vals.size))
for t1, element in enumerate(theta0_vals):
for t2, element2 in enumerate(theta1_vals):
thetaT = np.zeros(shape=(2,1))
weight = element
bias = element2
J_vals[t1, t2] = loss_function(X_train, y_train, weight, bias)
J_vals = J_vals.T
A, B = np.meshgrid(theta0_vals, theta1_vals)
C = J_vals
fig = plt.figure(figsize=(12, 5))
plt.subplot(121)
plt.plot(X_train, y_train, 'ro', label='Training data')
plt.title('Sales Prediction')
plt.axis([X_train.min()-X_train.std(), X_train.max()+X_train.std(),
y_train.min()-y_train.std(), y_train.max()+y_train.std()])
plt.grid(axis='both')
plt.xlabel('Wechat Ads Volumn(X1)')
plt.ylabel('Sales Volumn(Y)')
plt.legend(loc='lower right')
line, = plt.plot([], [], 'b-', label='Current Hypothesis')
annotation = plt.text(-2, 3, '', fontsize=20, color='green')
annotation.set_animated(True)
plt.subplot(122)
cp = plt.contour(A, B, C)
plt.colorbar(cp)
plt.title('Filled Contours Plot')
plt.xlabel('Bias')
plt.ylabel('Weight')
track, = plt.plot([],[],'r-')
point, = plt.plot([],[],'ro')
plt.tight_layout()
plt.close()
def init():
line.set_data([],[])
track.set_data([],[])
point.set_data([],[])
annotation.set_text('')
return line, track, point, annotation
def animate(i):
fit1_X = np.linspace(X_train.min()-X_train.std(),
X_train.max()+X_train.std(), 1000)
fit2_y = bias_history[i]+weight_history[i] * fit1_X
fit2_X = bias_history.T[:i]
fit2_y = weight_history.T[:i]
track.set_data(fit2_X, fit2_y)
line.set_data(fit1_X, fit1_y)
point.set_data(bias_history.T[i], weight_history.T[i])
annotation.set_text('Cost = %.4f' %(loss_history[i]))
return line, track, point, annotation
anim = animation.FuncAnimation(fig, animate, init_func=init,
frames=50, interval=0, blit=True)
anim.save('animation.gif', writer='imagemagick', fps = 500)
import io
import base64
from IPython.display import HTML
filename = 'animation.gif'
video = io.open(filename, 'r+b').read()
encoded = base64.b64encode(video)
HTML(data='''<img src="data:image/gif;base64,{0}" type="gif" />'''.format(encoded.decode('ascii')))
|